102번 - 연관 서브쿼리
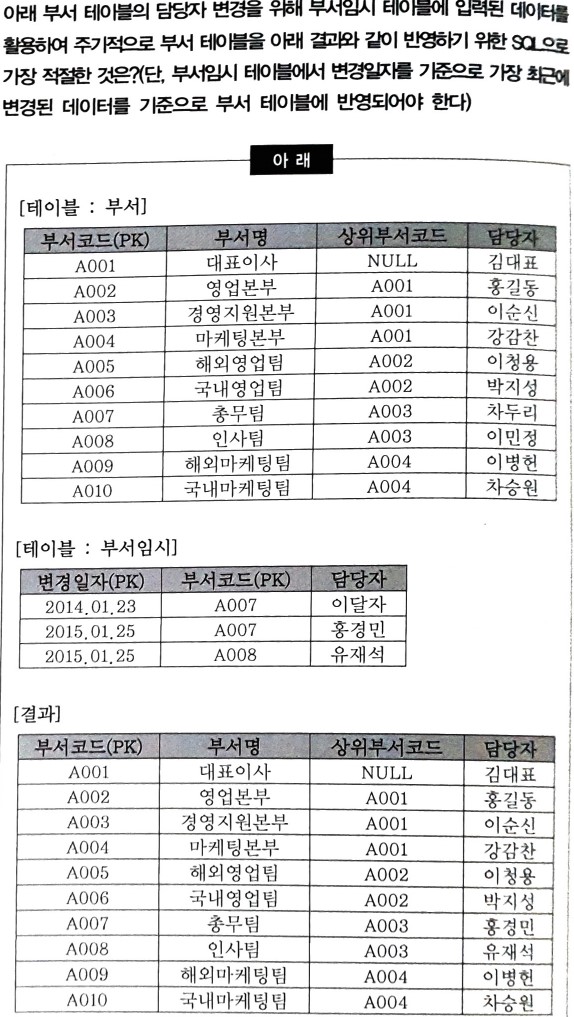
제시된 반영 조건과 테이블을 고려할 때,
부서임시 테이블에서는
각 부서코드 별로 변경일자가 가장 최근인 것을 고르고,
해당 행의 부서코드에 대응되는 부서 테이블의 행에서
부서 테이블의 담당자 칼럼의 값을 업데이트 해야 한다.
①번이 틀린 이유
WHERE 절에서
B.변경일자 = C.변경일자를 통해
뷰인 B와 부서임시 테이블 C 사이에 대하여
변경일자가 같은지 여부를 비교하므로 틀린 선지이다.
연관 서브쿼리가 이용되는 UPDATE에서 WHERE 절은
UPDATE의 대상이 되는 데이터 범위를 결정함.
이때, WHERE 절에는 테이블 A가 조건 대상으로 없으므로
해당 WHERE 절은 누락된다.
또는
부서 A SET 담당자 = (SELECT C.부서코드, 즉,
A의 담당자 칼럼에 부서코드 칼럼 값을 넣게 되므로
이는 맞지 않다.
②번이 틀린 이유
부서 A SET 담당자 = (SELECT C.부서코드, 즉,
A의 담당자 칼럼에 부서코드 칼럼 값을 넣게 되므로
이는 맞지 않다.
④번이 틀린 이유
B.변경일자 = '2015.01.15'로
고정된 값을 할당하고 있다.
이는 문제에서 요구하는 “주기적” 조건과 상충한다.
103번 - View에 대한 설명
View는
실제 데이터를 가지고 있지 않음.
단지, 뷰 정의View Definition만을 가짐.
실제 데이터를 가지고 있진 않지만
테이블의 수행 역할을 수행하므로
==> 가상테이블Virutal Table이라고도 함.
View 사용 시 장점
독립성
: 테이블 구조 변경되어도
뷰 사용하는 응용 프로그램은 변경 안 해도 됨.편리성
: 복잡합 질의를 뷰로 생성함으로써
관련 질의를 단순하게 작성 가능.
해당 형태의 SQL문 자주 사용 시
뷰 이용하면 편리하게 사용 가능.보안성
: 숨기고 싶은 정보(ex - 직원 급여정보) 존재 시
뷰 생성하면 해당 칼럼을 빼고 생성함으로써
사용자에게 정보를 감출 수 있다.
104번 - View 생성 코드
1
2
3
4
5
6
7
8
-- 기본 형식
CREATE VIEW [뷰 명칭];
-- 옵션
CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW 뷰이름 [ALIAS]
AS SELECT_statement
[WITH CHECK OPTION [CONSTRAINT [제약명]]]
[WITH READ ONLY [CONSTRAINT [제약명]]];
문제에 제시된 코드 예시
1
2
3
4
5
CREATE VIEW V_TBL
AS
SELECT *
FROM TBL
WHERE C1 = 'B' OR IS NULL;
105번 - GROUPING과 ROLLUP 알기
예시용 테이블과 데이터
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
DROP TABLE SERVICE;
CREATE TABLE SERVICE (
SERVICE_ID VARCHAR2(10) PRIMARY KEY,
SERVICE_NAME VARCHAR2(10)
);
DROP TABLE SERVICE_JOIN;
CREATE TABLE SERVICE_JOIN (
MEMBER_NUMBER NUMBER(5),
SERVICE_ID VARCHAR2(10),
JOIN_DATE DATE,
CONSTRAINT SERVICE_ID_FK FOREIGN KEY(SERVICE_ID) REFERENCES SERVICE(SERVICE_ID),
CONSTRAINT SERVICE_JOIN_PK PRIMARY KEY(MEMBER_NUMBER, SERVICE_ID)
);
INSERT INTO SERVICE VALUES('001', '서비스1');
INSERT INTO SERVICE VALUES('002', '서비스2');
INSERT INTO SERVICE VALUES('003', '서비스3');
INSERT INTO SERVICE VALUES('004', '서비스4');
INSERT INTO SERVICE_JOIN VALUES(1, '001', TO_DATE('2013-01-01', 'YYYY-MM-DD'));
INSERT INTO SERVICE_JOIN VALUES(1, '002', TO_DATE('2013-01-02', 'YYYY-MM-DD'));
INSERT INTO SERVICE_JOIN VALUES(2, '001', TO_DATE('2013-01-01', 'YYYY-MM-DD'));
INSERT INTO SERVICE_JOIN VALUES(2, '002', TO_DATE('2013-01-02', 'YYYY-MM-DD'));
INSERT INTO SERVICE_JOIN VALUES(2, '003', TO_DATE('2013-01-03', 'YYYY-MM-DD'));
INSERT INTO SERVICE_JOIN VALUES(3, '001', TO_DATE('2013-01-01', 'YYYY-MM-DD'));
INSERT INTO SERVICE_JOIN VALUES(3, '002', TO_DATE('2013-01-02', 'YYYY-MM-DD'));
INSERT INTO SERVICE_JOIN VALUES(3, '003', TO_DATE('2013-01-03', 'YYYY-MM-DD'));
ROLLUP
1
2
3
4
5
SELECT J.SERVICE_ID, COUNT(J.MEMBER_NUMBER) MEMBER_CNT
FROM SERVICE_JOIN J,
SERVICE S
WHERE J.SERVICE_ID = S.SERVICE_ID
GROUP BY ROLLUP(J.SERVICE_ID);
1
2
3
4
5
SELECT J.SERVICE_ID, COUNT(J.MEMBER_NUMBER) MEMBER_CNT
FROM SERVICE_JOIN J,
SERVICE S
WHERE J.SERVICE_ID = S.SERVICE_ID
GROUP BY J.SERVICE_ID;
위 두 개의 SQL문의 결과는 각각 다음과 같다.

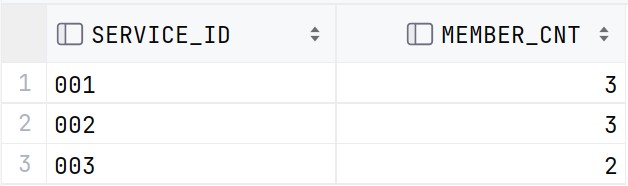
즉, ROLLUP은
GROUP BY로 집계된 각 그룹의 SUBTOTAL을 계산한다.
GROUPING
1
2
3
4
5
6
SELECT J.MEMBER_NUMBER,
GROUPING(J.MEMBER_NUMBER) AS GROUPING_MEM_NM
FROM SERVICE_JOIN J,
SERVICE S
WHERE J.SERVICE_ID = S.SERVICE_ID
GROUP BY ROLLUP(J.MEMBER_NUMBER);
1
2
3
4
5
6
SELECT J.SERVICE_ID,
GROUPING(J.SERVICE_ID) AS GROUPING_MEM_NM
FROM SERVICE_JOIN J,
SERVICE S
WHERE J.SERVICE_ID = S.SERVICE_ID
GROUP BY ROLLUP(J.SERVICE_ID);
위 두 SQL문에 대한 결과는 각각 다음과 같다.

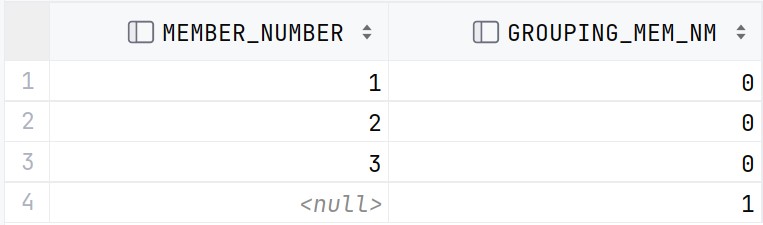
즉, GROUPING은
ROLLUP이나 CUBE로 소계가 계산된 결과에는
GROUPING(EXPR) = 1로 1이 표시되고,
그 이외에 대해서는 0으로 표시된다.
GROUPING과 CASE 활용
가이드 책 속의 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
-- ORACLE
SELECT
DECODE(GROUPING(DNAME), 1,
'All Departments', DNAME)
AS DNAME,
DECODE(GROUPING(JOB)), 1,
'All Jobs', JOB)
AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "TOtal Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB);
또는
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT
CASE GROUPING(DNAME) WHEN 1,
THEN 'All Departments'
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB) WHEN 1,
THEN 'All Jobs'
ELSE JOB
AS JOB,
COUNT(*) "Total Empl",
SUM(SAL) "TOtal Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB);
위 SQL문의 결과는 아래와 같다.
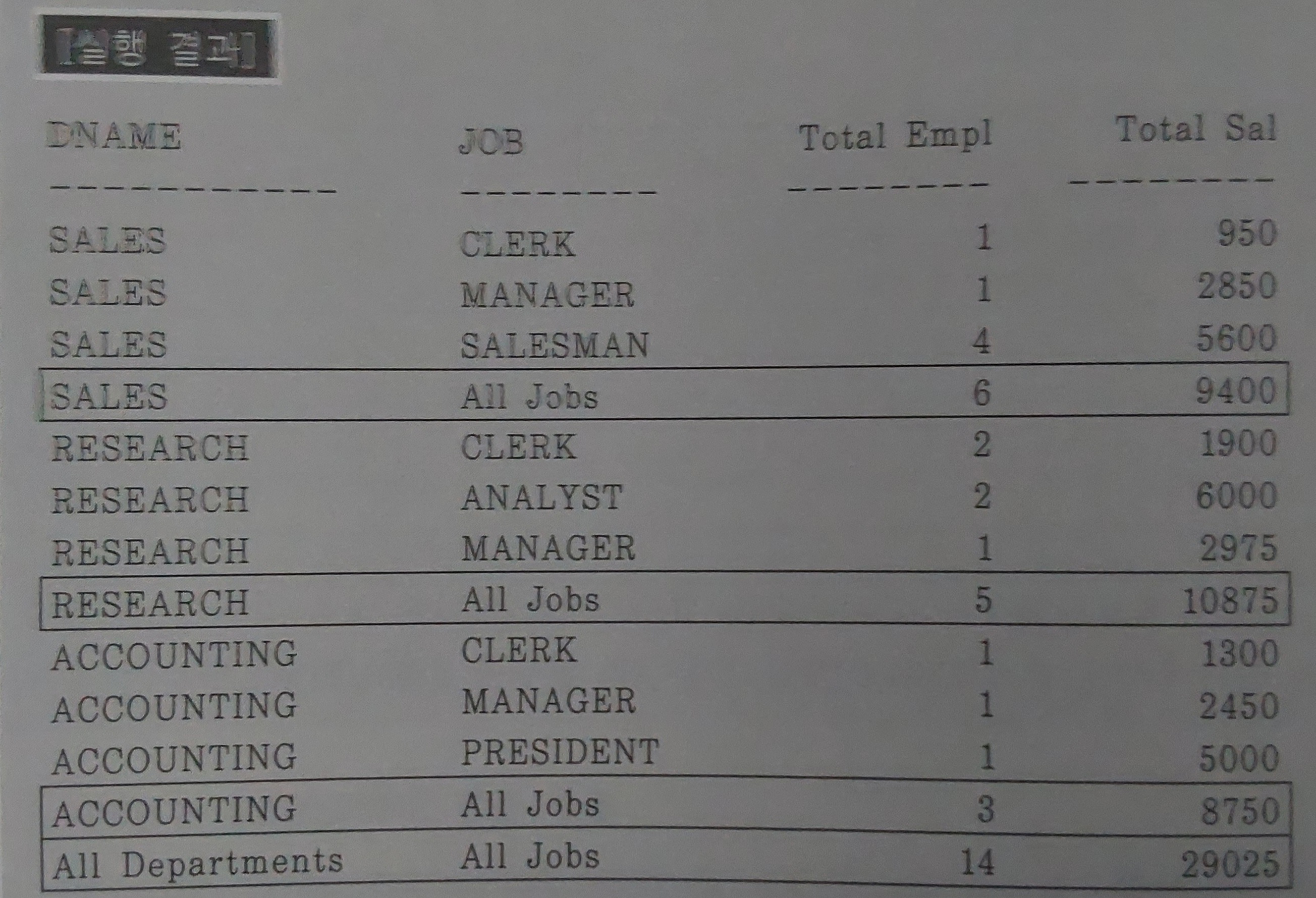
106번 - CUBE
결합 가능한 모든 값에 대하여 다차원 집계 생성
즉, 표시된 인수에 대한 계층별 집계 구할 수 있고,
이때, 이 인수들의 계층은 ROLLUP과는 달리 평등한 관계임.
CUBE의 Subtotal
CUBE의 GROUPING COLUMNS, 즉, 인수의 개수가 $N$일 때,
Subtotal의 개수는 $2^N$개가 된다.
예시 적용
예시로 사용하는 테이블과 데이터는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
CREATE TABLE SERVICE (
SERVICE_ID VARCHAR2(10) PRIMARY KEY,
SERVICE_NAME VARCHAR2(10)
);
CREATE TABLE SERVICE_JOIN (
MEMBER_NUMBER VARCHAR2(5),
SERVICE_ID VARCHAR2(10),
JOIN_DATE DATE,
JOIN_FEE NUMBER(5),
CONSTRAINT SERVICE_ID_FK FOREIGN KEY(SERVICE_ID) REFERENCES SERVICE(SERVICE_ID),
CONSTRAINT SERVICE_JOIN_PK PRIMARY KEY(MEMBER_NUMBER, SERVICE_ID)
);
1
2
3
4
5
6
7
8
9
10
11
12
13
INSERT INTO SERVICE VALUES('001', '서비스1');
INSERT INTO SERVICE VALUES('002', '서비스2');
INSERT INTO SERVICE VALUES('003', '서비스3');
INSERT INTO SERVICE VALUES('004', '서비스4');
INSERT INTO SERVICE_JOIN VALUES('1', '001', TO_DATE('2013-01-01', 'YYYY-MM-DD'), 10);
INSERT INTO SERVICE_JOIN VALUES('1', '002', TO_DATE('2013-01-02', 'YYYY-MM-DD'), 20);
INSERT INTO SERVICE_JOIN VALUES('2', '001', TO_DATE('2013-01-01', 'YYYY-MM-DD'), 15);
INSERT INTO SERVICE_JOIN VALUES('2', '002', TO_DATE('2013-01-02', 'YYYY-MM-DD'), 10);
INSERT INTO SERVICE_JOIN VALUES('2', '003', TO_DATE('2013-01-03', 'YYYY-MM-DD'), 20);
INSERT INTO SERVICE_JOIN VALUES('3', '001', TO_DATE('2013-01-01', 'YYYY-MM-DD'), 15);
INSERT INTO SERVICE_JOIN VALUES('3', '002', TO_DATE('2013-01-02', 'YYYY-MM-DD'), 30);
INSERT INTO SERVICE_JOIN VALUES('3', '003', TO_DATE('2013-01-03', 'YYYY-MM-DD'), 25);
위의 SQL문에 대한 결과는 아래와 같다.

1
2
3
4
5
6
/*
~~~~~
코드 동일
~~~~~
*/
GROUP BY CUBE (S.SERVICE_ID, J.MEMBER_NUMBER);
이때, CUBE의 인자 두 개의 순서를 바꾸면 아래와 같다.
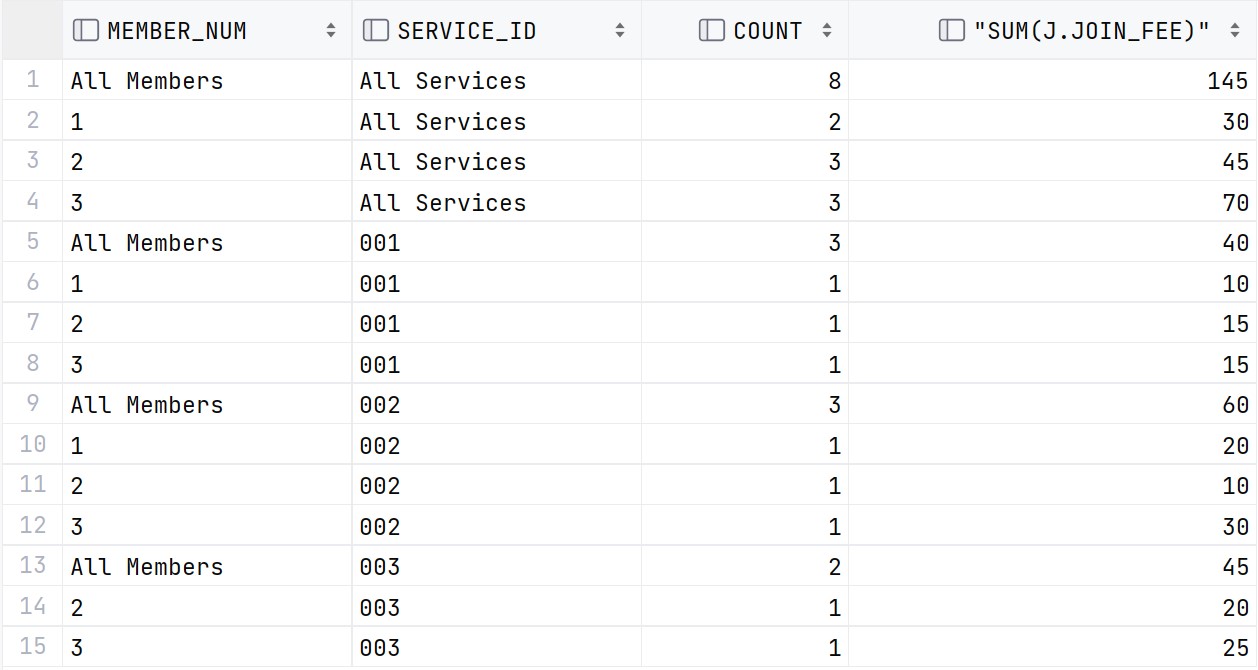
즉, 정렬 순서는 바뀔 수 있어도,
근본적인 데이터 자체는 동일하다.
MIN 함수 사용 이유!!
GROUP BY에 없는 칼럼은 집계함수 통해야 함!!
108번 - 집계 함수
①번이 틀린 이유
일반 함수로도 구현 가능
②번이 틀린 이유
GROUPING SETS는 인자인 칼럼에 대하여
같은 레벨로 각각의 소계를 출력하기 때문.
③번이 틀린 이유
집계 대상이 아닌 칼럼에 대해서는
NULL을 출력한다.
==> 그래서 CASE와 GROUPING으로 해당 부분 처리
109번 - CUBE와 GROUPING SETS
두 칼럼 A, B에 대하여 CUBE(A, B)는
각 subtotal의 값이
‘A에 대한 합계`, ‘B에 대한 합계’, ‘A, B에 대한 합계’, ‘총계’.
이렇게 4개가 되는데, 이는 2를 (인자의 개수)만큼 제곱한 값이다.
그리고,
GROUPING SETS의 인자는
‘A’, ‘B’, ‘A, B’, ‘[공집합](=총계)‘로,
CUBE의 경우와 동일하다고 할 수 있다.
112번 - 윈도우 함수, PARTITION, GROUP BY란?
윈도우 함수의 구문 형식
1
2
3
SELECT WINDOW_FUNCTION (ARGUMENTS) OVER
( [PARTITION BY [칼럼명]] [ORDER BY 절] [WINDOWING 절] )
FROM [테이블명];
윈도우 함수에는 OVER가 동반됨.
PARTITION BY
전체 집합을 기준에 의해 소그룹으로 나눔.
100번 - 서브쿼리 설명 3
스칼라 서브쿼리Scalar Subquery
: 한 행, 한 칼럼만을 반환하는 서브쿼리 e.g. - 선수 정보와 해당 선수가 속한 팀의 평균 키 함께 출력
==> 평균 키를 구하는 부분에 이용인라인 뷰Inline View
:FROM절에서 사용되는 서브쿼리
==> 인라인 뷰는 동적 뷰Dynamic View
115번 - ROW_NUMBER
동일한 값이라도 고유 순위를 부여함!!
즉, RANK나 DENSE_RANK 함수와 대조됨.
만약 순위까지 관리하고 싶다면
1
2
ROW_NUMBER() OVER
(ORDER BY [칼럼명] [ASC/DESC]) ~
위와 같이 ORDER BY 사용.