34번 - AND와 OR 우선순위
1
2
3
SELECT COUNT(*)
FROM EMP_TBL
WHERE EMPNO > 100 AND SAL >= 3000 OR EMPNO = 200;
위 문장에서 WHERE 절은 소괄호로 나누면 아래와 같다.
1
2
3
SELECT COUNT(*)
FROM EMP_TBL
WHERE ((EMPNO > 100 AND SAL >= 3000) OR EMPNO = 200);
즉, 위의 WHERE 절의 조건을 만족하는 행은
EMPNO와 SAL의 값이 각각 200, 3000인 행밖에 없다.
따라서 COUNT()에 의해 나오는 결과는 1이다.
37번 - ORACLE과 SQL Server의 차이점
''(empty string)에 대하여,
오라클은 해당 값을 NULL로 처리하는 반면에
SQL Server에선 그대로 '' 값으로 처리한다.
따라서,
제시된 테이블의 데이터 중에서 SQL Server 기준으로
서비스명=NULL인 조건에 부합하는 데이터는 존재하지 않는다.
즉, ④번 선지만이 옳다.
39번 - 선지별 SQL 문장 결과
①
1
2
3
4
5
6
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE SVC_END_DATE >= TO_DATE('20150101000000', 'YYYYMMDDHH24MISS')
AND SVC_END_DATE <= TO_DATE('20150131235959', 'YYYYMMDDHH24MISS')
AND CONCAT(JOIN_YMD, JOIN_HH) = '2014120100'
GROUP BY SVC_ID;
WHERE 절에서
SVC_END_DATE의 범위가 [2015/01/01/00:00:00, 2015/01/31/23:59:59]이고,
JOIN_YMD||JOIN_HH의 값은 ‘2014120100’이어야 한다.
②
1
2
3
4
5
6
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE SVC_END_DATE >= TO_DATE('20150101', 'YYYYMMDD')
AND SVC_END_DATE < TO_DATE('20150201', 'YYYYMMDD')
AND (JOIN_YMD, JOIN_HH) IN (('2014120100', '00'))
GROUP BY SVC_ID;
WHERE 절에서
SVC_END_DATE의 범위가 [2015/01/01, 2015/02/01)이고,
JOIN_YMD와 JOIN_HH의 값은 각각 ‘2014120100’, ‘00’이어야 한다.
③
1
2
3
4
5
6
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE '201501' = TO_CHAR(SVC_END_DATE, 'YYYYMM')
AND JOIN_YMD = '20141201'
AND JOIN_HH = '00'
GROUP BY SVC_ID;
WHERE 절에서
SVC_END_DATE의 YYYYMM 부분의 값이 ‘201501’이고,
JOIN_YMD와 JOIN_HH의 값은 각각 ‘20141201’, ‘00’이어야 한다.
즉, SVC_END_DATE에서 DDHH24MISS까지 비교된 것은 아니므로
이것은 곧 DDHH24MISS의 값이 ‘000000’부터 ‘235959’까지의 범위이다.
④
1
2
3
4
5
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE TO_DATE('201501', 'YYYYMM') = SVC_END_DATE
AND JOIN_YMD||JOIN_HH = '2014120100'
GROUP BY SVC_ID;
WHERE 절에서
SVC_END_DATE의 값이 YYYYMM 형식인 ‘201501’이어야 하고
JOIN_YMD||JOIN_HH의 값은 ‘2014120100’이어야 한다.
따라서, 결과가 다른 것은 ④번이다.
42번 - 날짜형 데이터의 연산
날짜형 데이터의 연산을 알아보기 위해
아래와 같은 코드를 작성한 뒤 실행해보았다.
즉, ‘2015년 1월 1일 22시 20분’이라는 날짜 데이터에
데이터 원본, +1시간, +1분을 각각 칼럼으로 표시한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
SELECT TO_CHAR(
TO_DATE(
'2015.01.01 22:20',
'YYYY.MM.DD HH24:MI'
)
,'YYYY.MM.DD HH24:MI'
) AS ORIG,
TO_CHAR(
TO_DATE(
'2015.01.01 22:20',
'YYYY.MM.DD HH24:MI'
)
+ 1/24
,'YYYY.MM.DD HH24:MI'
) AS PLUS_1H,
TO_CHAR(
TO_DATE(
'2015.01.01 22:20',
'YYYY.MM.DD HH24:MI'
)
+ 1/24/60
,'YYYY.MM.DD HH24:MI'
) AS PLUS_1M
FROM DUAL;
결과는 다음과 같다.

이러한 결과에 따라 다음과 같이 판단 가능하다.
1/24는 1시간이다.1/24/60은 1분이다.
즉, 24시간을 기준으로 직관적인 연산으로 간주해도 될 것 같다.
43번 - CASE WHEN
ORACLE에서 PL/SQL 가이드/레퍼런스를 통해 안내하고 있는
CASE 문에 대한 설명은 다음과 같다.
searched_case_statement
1
2
3
4
[ <<label_name>> ]
CASE { WHEN boolean_expression THEN {statement;} ... }...
[ ELSE {statement;}... ]
END CASE [ label_name ];
simple_case_statement
1
2
3
4
5
[ <<label_name>> ]
CASE case_operand
{ WHEN when_operand THEN {statement;} ... }...
[ ELSE {statement;}... ]
END CASE [ label_name ];
즉, 문제에서 제시된 SEARCHED_CASE를
SIMPLE_CASE로 변환한 것은 다음과 같다.
1
2
3
4
5
6
7
SELECT LOC,
CASE LOC
WHEN 'NEW YORK'
THEN 'EAST'
ELSE 'ETC'
END AS AREA
FROM DEPT;
44번 - NVL, ISNULL
NVL(ORACLE)
1
NVL(expr1, expr2)
NVLlets you replace null (returned as a blank) with a string in the results of a query. Ifexpr1is null, thenNVLreturnsexpr2. Ifexpr1is not null, thenNVLreturnsexpr1.
출처: Database SQL Reference, ORACLE
ISNULL(SQL Server)
1
ISNULL(check_expression , replacement_value)
Replaces NULL with the specified replacement value.
출처: SQL Server technical documentation , Microsoft
★ 둘 다 데이터 타입 동일!!
즉, expr1/check_expression과
expr2/replacement_value의 타입이 동일해야 함!!
45번 - NULL과 비교 시 주의점
어떠한 특정 값이 NULL인지 아닌지 비교할 때는
IS/IS NOT을 쓴다!!!
=이나 <> 쓰는 거 아님!!!
47번 - NULL 및 Zero 연산
NULL과의 연산은
결과가 모두 NULL이다!!
0이 제수除數일 때
그 결과는 0도 아니고 NULL도 아니고,
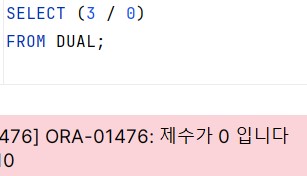
ORA-01476 넘버의 에러가 발생한다!!
이 에러는 ZERO_DIVIDE라는 이름으로 정의되어 있다.
(출처: Database PL/SQL Developer’s Guide, ORACLE)
48번 - COALESCE
COALESCE란?
COALESCEreturns the first non-nullexprin the expression list. You must specify at least two expressions. If all occurrences ofexprevaluate to null, then the function returns null.
출처: Database SQL Reference, ORACLE
함수의 각 매개변수들 중에서
첫 번째로 NULL이 아닌 값들을 반환하므로
결과는 $1 + 2 + 3 = 6$이다.
만약 인자들의 순서를 바꾼다면???
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
CREATE TABLE TAB2 (
C1 NUMBER(10),
C2 NUMBER(10),
C3 NUMBER(10)
);
INSERT INTO TAB2 VALUES(1, 2, 3);
INSERT INTO TAB2 VALUES(NULL, 2, 3);
INSERT INTO TAB2 VALUES(NULL, NULL, 3);
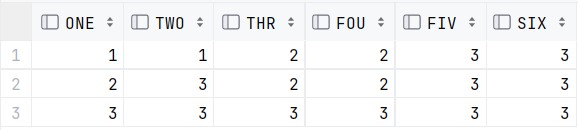
SELECT COALESCE(C1, C2, C3) AS ONE,
COALESCE(C1, C3, C2) AS TWO,
COALESCE(C2, C1, C3) AS THR,
COALESCE(C2, C3, C1) AS FOU,
COALESCE(C3, C1, C2) AS FIV,
COALESCE(C3, C2, C1) AS SIX
FROM TAB2;
위와 같이 수행하였을 때,
아래와 같은 결과를 확인 가능하다.
(근데, 이거 반복문으로 할 수 있을 것 같은데
SQL에선 어떻게 해야할지 아직 안 찾아봤다…)
50번 - AVG
AVG는 NULL을 무시함!!
AVGreturns average value ofexpr.This function takes as an argument any numeric data type or any nonnumeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument.
출처: “Database SQL Language Reference - AVG”, ORACLE
다른 집계함수Aggregate Functions도 마찬가지임!!
All aggregate functions except
COUNT(*),GROUPING, andGROUPING_IDignore nulls.
출처: “Database SQL Language Reference - Aggregate Functions”, ORACLE
52번 - 빈칸 SQL 고르기

문제에서 제시하는 출력 명세
- 광고매체 ID별 최초로 게시한
- 광고명
- 광고시작일자
그리고,
광고게시 테이블에서
광고ID와 광고매체ID 칼럼이 각각
광고, 광고매체 엔터티의 칼럼을 참조한다.
또한, 제시된 SQL문에서
1
2
3
4
5
6
7
8
SELECT C.광고매체명, B.광고명, A.광고시작일자
FROM 광고게시 A, 광고 B, 광고매체 C
( ) D
WHERE A.광고시작일자 = D.광고시작일자
AND A.광고매체ID = D.광고매체ID
AND A.광고ID = B.광고ID
AND A.광고매체ID = C.광고매체ID
ORDER BY C.광고매체명;
Alias가 D로 지정된 테이블은 최소한
광고시작일자와 광고매체ID가 칼럼임을 알 수 있고,
제시문에 의거할 때
“최초로 게시한 광고시작일자”를 선택하는 SQL 문장은
확인할 수 없다.
1
2
AND A.광고ID = B.광고ID
AND A.광고매체ID = C.광고매체ID
이 두 문장은 FK 관계와 상관이 있는 것이고,
1
2
WHERE A.광고시작일자 = D.광고시작일자
AND A.광고매체ID = D.광고매체ID
이 두 문장은 D를 정확히 모르기 때문이다.
즉, 달리 말하면, D에
“최초로 게시한” 정보를 선택하는 문장이 있다고 할 수 있다.
또한,
“최초”라는 걸 가려내기 위해 비교가 가능한 값은
DATE 타입인 광고시작일자 칼럼의 값이다.
따라서, 광고매체ID가 MIN() 함수 인자로 있는
③번, ④번 선지는 부적절하다.
그리고,
이미 제시된 SQL문에서
1
2
3
AND A.광고매체ID = D.광고매체ID
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
AND A.광고매체ID = C.광고매체ID
이렇게 A.광고매체ID를 매개로 하여
세 개의 칼럼의 값이 같은지 여부가 비교되었으므로
①번 선지는 부적절하다.
57번 - NULL의 ORDER BY
ORDER BY에서 NULL을 기준으로 하게 될 시엔
ORACLE에서는 NULL을 가장 큰 값으로 간주!
SQL Server에서는 가장 작은 값으로 간주!
60번 - TOP() WITH TIES
TOP() WITH TIES는
SQL Server의 문법!!!
정리
- ORACLE
ROWNUM
- SQL Server
SELECT TOP()
- MySQL
LIMIT